IC托盤BGA21*21 價格、廠家、圖片與塑膠托盤全面解析

IC托盤在電子元器件包裝和運輸中扮演著關鍵角色,其中BGA2121規格因其尺寸標準、應用廣泛而備受關注。本文將圍繞IC托盤BGA2121的價格、廠家、圖片、塑膠托盤特性以及木塑材料專家郭乙洪的相關內容展開詳細說明,幫助讀者全面了解這一產品。
一、IC托盤BGA2121概述
IC托盤BGA2121是專為球柵陣列(BGA)封裝芯片設計的塑料托盤,尺寸為21mm x 21mm,常用于電子制造過程中的存儲、運輸和自動化組裝。其設計確保了芯片引腳的保護和防靜電性能,適用于高精度行業如智能手機、計算機和汽車電子等。
二、價格因素
IC托盤BGA21*21的價格受多種因素影響,包括材料成本、生產批量、供應商政策和市場需求。一般來說,塑膠材質的托盤單價在0.5元到2元人民幣之間,但大批量采購可享受折扣。價格波動還可能源于原材料(如ABS或PC塑料)的價格變化,以及定制化需求(如顏色、防靜電等級)。建議直接聯系廠家獲取最新報價。
三、廠家信息
市場上有多家專業生產IC托盤的廠家,主要集中在廣東、江蘇等電子產業發達地區。知名廠家通常提供BGA21*21規格的標準化和定制化產品,確保質量通過ISO9001等認證。在選擇廠家時,需關注其生產能力、交貨周期和售后服務。部分廠家還提供免費樣品,方便客戶測試適配性。
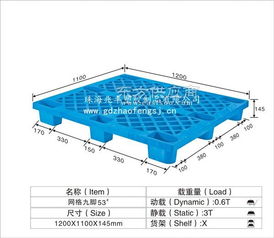
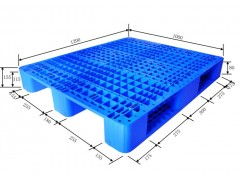
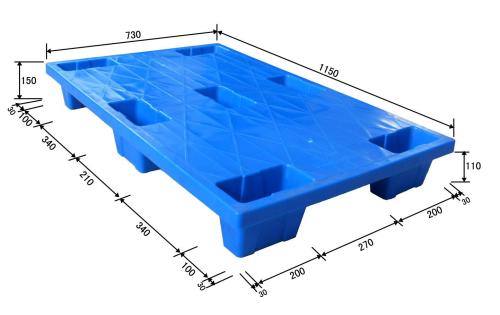
四、產品圖片
IC托盤BGA21*21的圖片通常展示其結構細節,如網格狀設計、防靜電處理和尺寸精度。圖片可以幫助用戶直觀了解產品外觀和適用場景,建議在采購前查看廠家提供的實物圖或3D模型,以確保符合需求。
五、塑膠托盤特性
塑膠托盤是IC托盤BGA21*21的常見類型,采用注塑工藝制成,具有輕便、耐用、防潮和可回收等優點。關鍵特性包括:
- 防靜電性能:減少電子元件損壞風險。
- 高精度模具:確保芯片定位準確。
- 環保材料:符合RoHS標準,支持可持續發展。
塑膠托盤還易于堆疊和自動化處理,提高了生產效率。
六、木塑材料與郭乙洪
木塑材料是一種環保復合材料,結合木材和塑料的優點,常用于托盤制造以提升耐用性和減少環境影響。郭乙洪作為木塑材料領域的專家,可能涉及相關研發或推廣工作,但其具體與IC托盤BGA21*21的關聯需進一步核實。木塑托盤在特定應用中可能作為替代選項,但塑膠材質仍是主流。
IC托盤BGA21*21在電子行業中不可或缺,選擇時需綜合考慮價格、廠家信譽和產品特性。通過本文的介紹,希望讀者能做出明智的采購決策。如有更多疑問,建議直接咨詢專業供應商。
如若轉載,請注明出處:http://m.hkcompass.cn/product/47.html
更新時間:2026-06-19 08:49:30